Масштабирование
В этом примере вы узнаете, как настроить простой масштабируемый кластер ClickHouse. Настроено пять серверов: два используются для шардинга данных, а остальные три сервера выполняют функции координации.
Архитектура кластера, который вы будете настраивать, показана ниже:
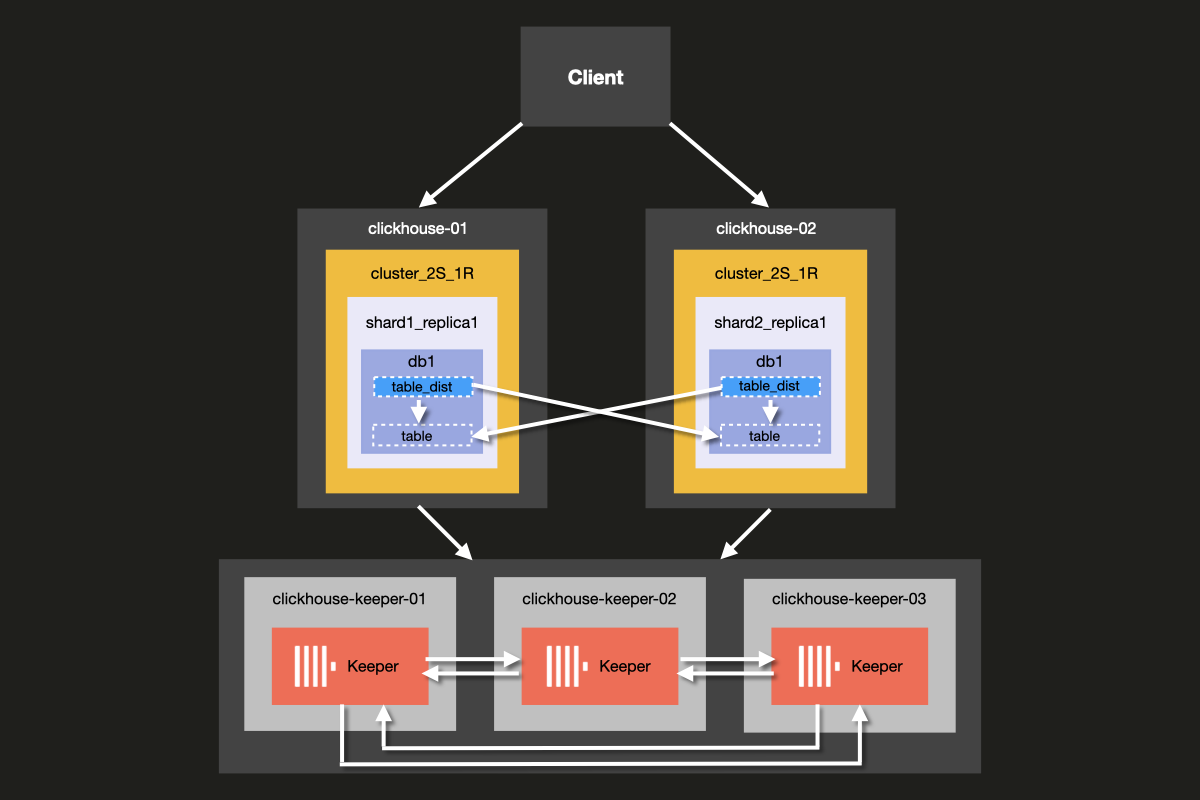
Although it is possible to run ClickHouse Server and ClickHouse Keeper combined on the same server, we strongly recommend using dedicated hosts for ClickHouse keeper in production environments, which is the approach we will demonstrate in this example.
Keeper servers can be smaller, and 4GB RAM is generally enough for each Keeper server until your ClickHouse Servers grow large.
Предварительные требования
- Вы уже развернули локальный сервер ClickHouse
- Вы знакомы с основами конфигурирования ClickHouse, такими как конфигурационные файлы
- На вашей машине установлен Docker
Настройка структуры каталогов и тестовой среды
The following steps will walk you through setting up the cluster from scratch. If you prefer to skip these steps and jump straight to running the cluster, you can obtain the example files from the examples repository 'docker-compose-recipes' directory.
В этом руководстве вы будете использовать Docker Compose для развёртывания кластера ClickHouse. Эту конфигурацию можно адаптировать для работы на отдельных локальных машинах, виртуальных машинах или облачных инстансах.
Выполните следующие команды для создания структуры каталогов для этого примера:
Добавьте следующий файл docker-compose.yml в каталог clickhouse-cluster:
Создайте следующие подкаталоги и файлы:
- The
config.ddirectory contains ClickHouse server configuration fileconfig.xml, in which custom configuration for each ClickHouse node is defined. This configuration gets combined with the defaultconfig.xmlClickHouse configuration file that comes with every ClickHouse installation. - The
users.ddirectory contains user configuration fileusers.xml, in which custom configuration for users is defined. This configuration gets combined with the default ClickHouseusers.xmlconfiguration file that comes with every ClickHouse installation.
It is a best practice to make use of the config.d and users.d directories when
writing your own configuration, rather than directly modifying the default configuration
in /etc/clickhouse-server/config.xml and etc/clickhouse-server/users.xml.
The line
Ensures that the configuration sections defined in the config.d and users.d
directories override the default configuration sections defined in the default
config.xml and users.xml files.
Настройка узлов ClickHouse
Настройка сервера
Теперь измените каждый пустой файл конфигурации config.xml, расположенный по пути
fs/volumes/clickhouse-{}/etc/clickhouse-server/config.d. Строки, выделенные
ниже, должны быть изменены для каждого узла отдельно:
| Каталог | Файл |
|---|---|
fs/volumes/clickhouse-01/etc/clickhouse-server/config.d | config.xml |
fs/volumes/clickhouse-02/etc/clickhouse-server/config.d | config.xml |
Каждый раздел указанного выше конфигурационного файла подробно описан ниже.
Сеть и логирование
External communication to the network interface is enabled by activating the listen host setting. This ensures that the ClickHouse server host is reachable by other hosts:
The port for the HTTP API is set to 8123:
The TCP port for interaction by ClickHouse's native protocol between clickhouse-client
and other native ClickHouse tools, and clickhouse-server and other clickhouse-servers
is set to 9000:
Логирование настраивается в блоке <logger>. Данная конфигурация создаёт
отладочный журнал, который будет ротироваться при достижении размера 1000M три раза:
Дополнительную информацию о настройке логирования см. в комментариях стандартного файла конфигурации ClickHouse.
Конфигурация кластера
Конфигурация кластера задаётся в блоке <remote_servers>.
Здесь задано имя кластера cluster_2S_1R.
Блок <cluster_2S_1R></cluster_2S_1R> определяет топологию кластера
с помощью параметров <shard></shard> и <replica></replica> и служит
шаблоном для распределённых DDL-запросов — запросов, выполняемых на всём
кластере с использованием конструкции ON CLUSTER. По умолчанию распределённые DDL-запросы
разрешены, но их можно отключить параметром allow_distributed_ddl_queries.
internal_replication по умолчанию оставлен со значением false, так как на каждый шард приходится только одна реплика.
For each server, the following parameters are specified:
| Parameter | Description | Default Value |
|---|---|---|
host | The address of the remote server. You can use either the domain or the IPv4 or IPv6 address. If you specify the domain, the server makes a DNS request when it starts, and the result is stored as long as the server is running. If the DNS request fails, the server does not start. If you change the DNS record, you need to restart the server. | - |
port | The TCP port for messenger activity (tcp_port in the config, usually set to 9000). Not to be confused with http_port. | - |
Конфигурация Keeper
Секция <ZooKeeper> указывает ClickHouse, где запущен ClickHouse Keeper (или ZooKeeper).
Поскольку используется кластер ClickHouse Keeper, необходимо указать каждый узел <node> кластера
вместе с его именем хоста и номером порта с помощью тегов <host> и <port> соответственно.
Настройка ClickHouse Keeper описана на следующем шаге руководства.
Хотя ClickHouse Keeper можно запустить на том же сервере, что и ClickHouse Server, для production-окружений мы настоятельно рекомендуем использовать выделенные хосты для ClickHouse Keeper.
Конфигурация макросов
Кроме того, секция <macros> используется для определения подстановки параметров для
реплицируемых таблиц. Они перечислены в system.macros и позволяют использовать подстановки
типа {shard} и {replica} в запросах.
Эти параметры определяются индивидуально в зависимости от конфигурации кластера.
Настройка пользователя
Теперь измените каждый пустой конфигурационный файл users.xml, расположенный в
fs/volumes/clickhouse-{}/etc/clickhouse-server/users.d, следующим образом:
| Содержание | Файл |
|---|---|
fs/volumes/clickhouse-01/etc/clickhouse-server/users.d | users.xml |
fs/volumes/clickhouse-02/etc/clickhouse-server/users.d | users.xml |
В данном примере пользователь по умолчанию настроен без пароля для упрощения. На практике это не рекомендуется.
В данном примере файл users.xml одинаков для всех узлов кластера.
Настройка ClickHouse Keeper
Настройка Keeper
In order for replication to work, a ClickHouse keeper cluster needs to be set up and configured. ClickHouse Keeper provides the coordination system for data replication, acting as a stand in replacement for Zookeeper, which could also be used. ClickHouse Keeper is, however, recommended, as it provides better guarantees and reliability and uses fewer resources than ZooKeeper. For high availability and to keep quorum, it is recommended to run at least three ClickHouse Keeper nodes.
ClickHouse Keeper can run on any node of the cluster alongside ClickHouse, although it is recommended to have it run on a dedicated node which allows scaling and managing the ClickHouse Keeper cluster independently of the database cluster.
Create the keeper_config.xml files for each ClickHouse Keeper node
using the following command from the root of the example folder:
Modify the empty configuration files which were created in each
node directory fs/volumes/clickhouse-keeper-{}/etc/clickhouse-keeper. The
highlighted lines below need to be changed to be specific to each node:
| Каталог | Файл |
|---|---|
fs/volumes/clickhouse-keeper-01/etc/clickhouse-keeper | keeper_config.xml |
fs/volumes/clickhouse-keeper-02/etc/clickhouse-keeper | keeper_config.xml |
fs/volumes/clickhouse-keeper-03/etc/clickhouse-keeper | keeper_config.xml |
Each configuration file will contain the following unique configuration (shown below).
The server_id used should be unique for that particular ClickHouse Keeper node
in the cluster and match the server <id> defined in the <raft_configuration> section.
tcp_port is the port used by clients of ClickHouse Keeper.
The following section is used to configure the servers that participate in the quorum for the raft consensus algorithm:
ClickHouse Cloud removes the operational burden associated with managing shards and replicas. The platform automatically handles high availability, replication, and scaling decisions. Compute and storage are separate and scale based on demand without requiring manual configuration or ongoing maintenance.
Проверка настройки
Убедитесь, что Docker запущен на вашем компьютере.
Запустите кластер командой docker-compose up из корневого каталога cluster_2S_1R:
Вы увидите, как docker начнет загружать образы ClickHouse и Keeper, а затем запустит контейнеры:
Чтобы проверить, что кластер работает, подключитесь к clickhouse-01 или clickhouse-02 и выполните следующий запрос. Ниже приведена команда для подключения к первому узлу:
При успешном подключении вы увидите командную строку клиента ClickHouse:
Выполните следующий запрос, чтобы проверить, какие топологии кластера определены для каких хостов:
Выполните следующий запрос, чтобы проверить состояние кластера ClickHouse Keeper:
The mntr command is also commonly used to verify that ClickHouse Keeper is
running and to get state information about the relationship of the three Keeper nodes.
In the configuration used in this example, there are three nodes working together.
The nodes will elect a leader, and the remaining nodes will be followers.
The mntr command gives information related to performance, and whether a particular
node is a follower or a leader.
You may need to install netcat in order to send the mntr command to Keeper.
Please see the nmap.org page for download information.
Run the command below from a shell on clickhouse-keeper-01, clickhouse-keeper-02, and
clickhouse-keeper-03 to check the status of each Keeper node. The command
for clickhouse-keeper-01 is shown below:
The response below shows an example response from a follower node:
The response below shows an example response from a leader node:
Таким образом, вы успешно настроили кластер ClickHouse с одним шардом и двумя репликами. На следующем шаге вы создадите таблицу в кластере.
Создание базы данных
Теперь, когда вы убедились, что кластер правильно настроен и запущен, вы создадите ту же таблицу, что и в руководстве по примеру набора данных UK property prices. Она содержит около 30 миллионов записей о ценах на недвижимость в Англии и Уэльсе с 1995 года.
Подключитесь к клиенту каждого хоста, выполнив следующие команды в отдельных вкладках или окнах терминала:
Вы можете выполнить приведённый ниже запрос из clickhouse-client на каждом хосте, чтобы убедиться, что помимо стандартных баз данных других пока не создано:
Из клиента clickhouse-01 выполните следующий распределённый DDL-запрос с использованием
конструкции ON CLUSTER для создания новой базы данных uk:
Вы можете снова выполнить тот же запрос, что и ранее, из клиента каждого хоста,
чтобы убедиться, что база данных была создана во всём кластере, несмотря на то, что
запрос выполнялся только на clickhouse-01:
Создание таблицы в кластере
Теперь, когда база данных создана, создайте таблицу. Выполните следующий запрос из любого клиента на хосте:
Обратите внимание, что этот запрос идентичен запросу из исходной инструкции CREATE в
руководстве по примеру набора данных цен на недвижимость в Великобритании,
за исключением конструкции ON CLUSTER.
Конструкция ON CLUSTER предназначена для распределённого выполнения DDL-запросов (Data Definition Language),
таких как CREATE, DROP, ALTER и RENAME, что обеспечивает применение
изменений схемы на всех узлах кластера.
Вы можете выполнить приведённый ниже запрос из клиента каждого хоста, чтобы убедиться, что таблица создана во всём кластере:
Прежде чем вставлять данные о ценах на недвижимость в Великобритании, выполним небольшой эксперимент, чтобы посмотреть, что происходит при вставке данных в обычную таблицу с любого из хостов.
Создайте тестовую базу данных и таблицу, выполнив следующий запрос с любого из хостов:
Теперь из clickhouse-01 выполните следующий запрос INSERT:
Переключитесь на clickhouse-02 и выполните следующий запрос INSERT:
Теперь из clickhouse-01 или clickhouse-02 выполните следующий запрос:
Обратите внимание, что в отличие от таблицы ReplicatedMergeTree возвращается только та строка, которая была вставлена в таблицу на конкретном хосте, а не обе строки.
Для чтения данных из двух шардов требуется интерфейс, способный обрабатывать запросы ко всем шардам, объединяя данные из обоих шардов при выполнении SELECT-запросов и вставляя данные в оба шарда при выполнении INSERT-запросов.
В ClickHouse этот интерфейс называется распределённой таблицей, которую мы создаём с помощью движка таблиц Distributed. Рассмотрим, как это работает.
Создание распределённой таблицы
Создайте распределённую таблицу с помощью следующего запроса:
В данном примере функция rand() выбрана в качестве ключа шардирования, чтобы
операции вставки случайным образом распределялись по шардам.
Теперь выполните запрос к распределённой таблице с любого из хостов — вы получите обе строки, вставленные на обоих хостах, в отличие от предыдущего примера:
Выполним те же действия для данных о ценах на недвижимость в Великобритании. С любого клиента
выполните следующий запрос для создания распределённой таблицы на основе существующей таблицы,
которую мы создали ранее с помощью ON CLUSTER:
Вставка данных в распределённую таблицу
Теперь подключитесь к любому из хостов и добавьте данные:
После вставки данных можно проверить количество строк с помощью распределённой таблицы:
Если выполнить следующий запрос на любом из хостов, вы увидите, что данные
распределены более или менее равномерно по шардам (имейте в виду, что выбор шарда
для вставки определялся функцией rand(), поэтому ваши результаты могут отличаться):
Что произойдет, если один из хостов выйдет из строя? Давайте смоделируем это, остановив
clickhouse-01:
Проверьте, что хост недоступен, выполнив команду:
Теперь из clickhouse-02 выполните тот же запрос SELECT, который мы выполняли ранее, к распределённой таблице:
К сожалению, наш кластер не обладает отказоустойчивостью. При отказе одного из хостов кластер считается неработоспособным, и запрос завершается с ошибкой — в отличие от реплицированной таблицы из предыдущего примера, где мы могли вставлять данные даже при отказе одного из хостов.
Заключение
Преимущество такой топологии кластера состоит в том, что данные распределяются по отдельным хостам и используют вдвое меньше дискового пространства на узел. Что ещё важнее, запросы обрабатываются на обоих шардах, что более эффективно с точки зрения использования памяти и снижает объём I/O на каждый хост.
Основной недостаток такой топологии кластера, разумеется, в том, что потеря одного из хостов делает обработку запросов невозможной.
В следующем примере мы рассмотрим, как настроить кластер с двумя шардами и двумя репликами, обеспечивающий как масштабируемость, так и отказоустойчивость.
